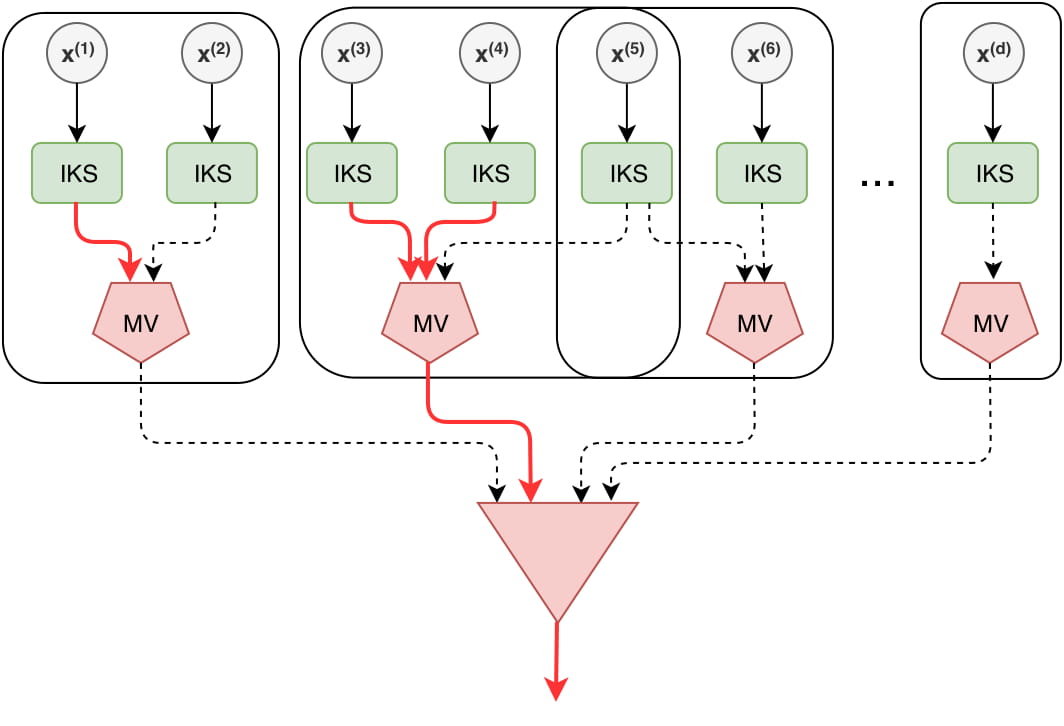
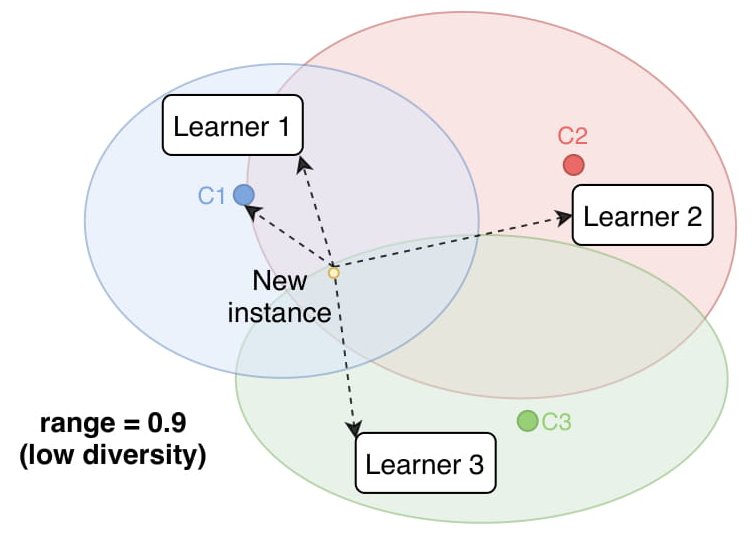
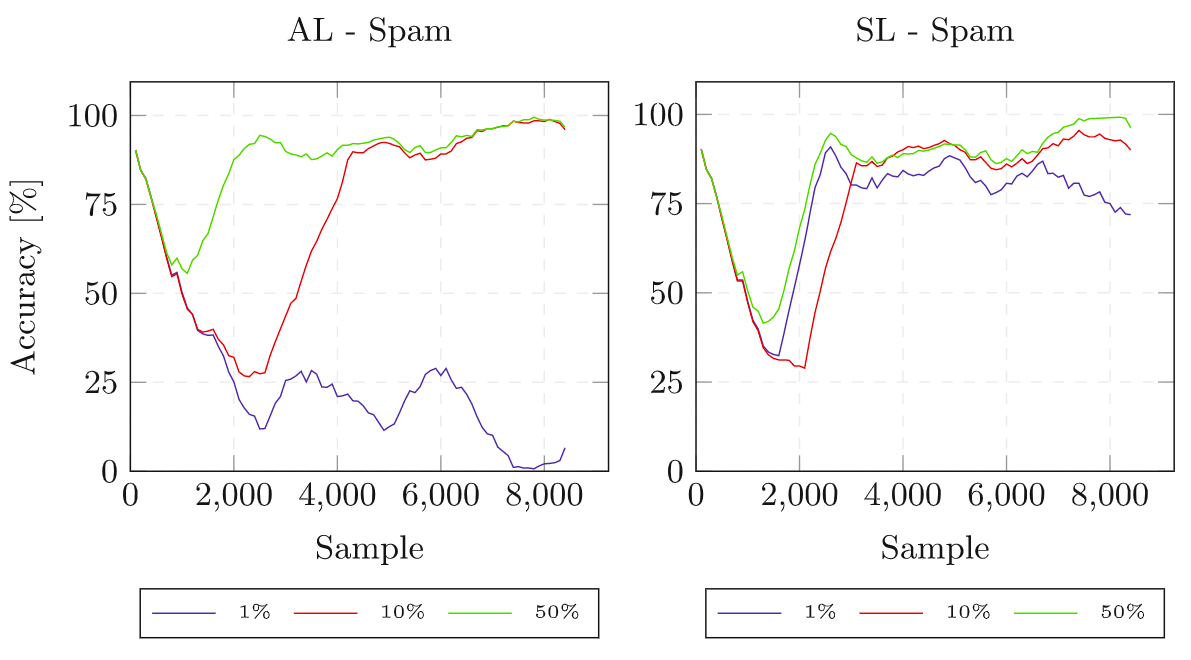
About Me
I am a research scientist at Meta (Silicon Valley, USA), with Ph.D. in ML/AI. Mostly a generalist, devoted to developing universal approaches and supporting their applications to real-world issues. Specialized in advancing online/incremental learning algorithms that are able to effectively aggregate stable patterns and adapt to changes in dynamic environments.
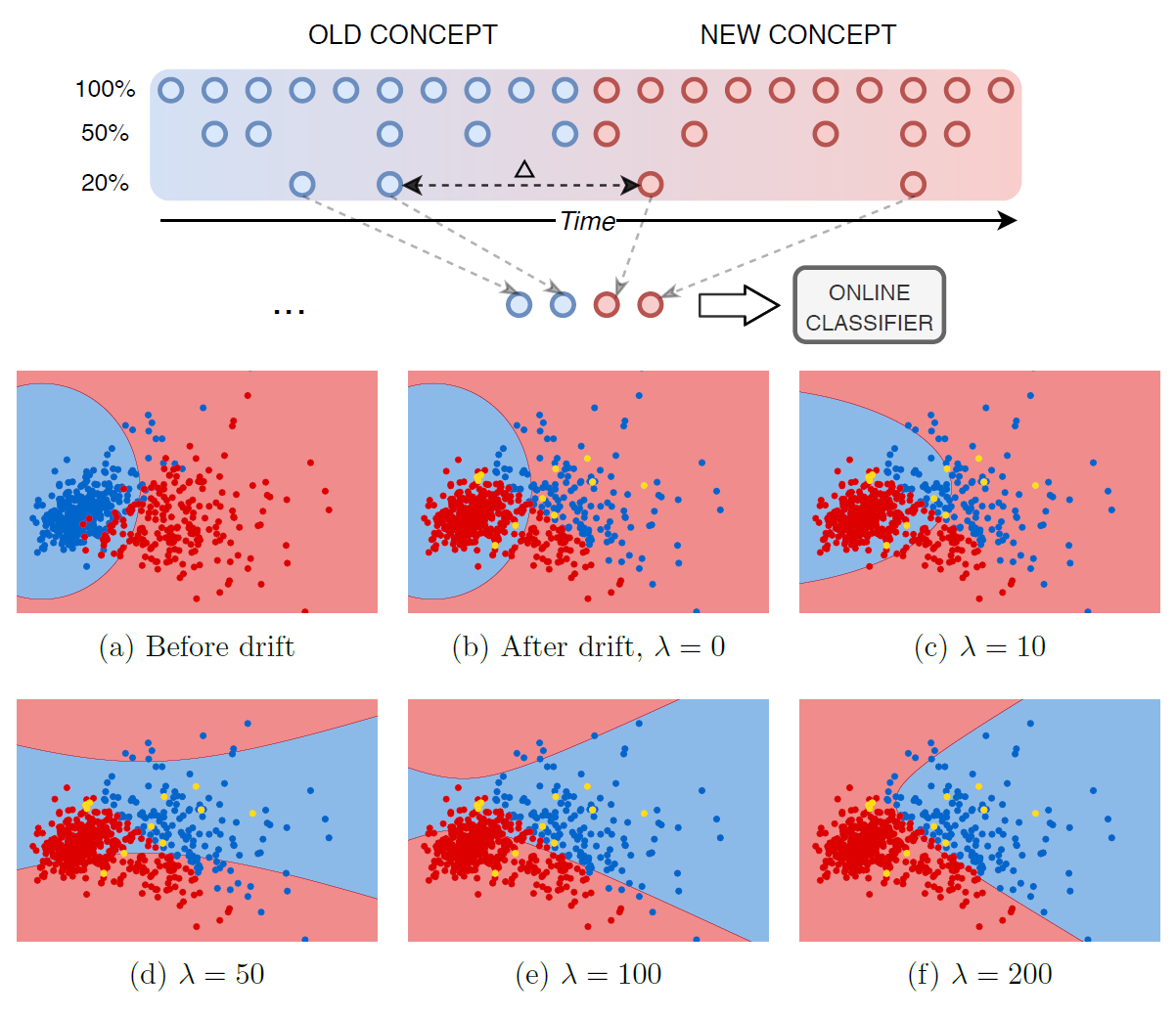
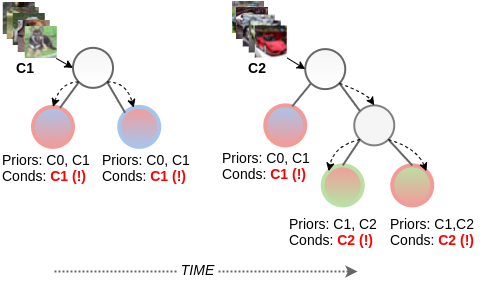
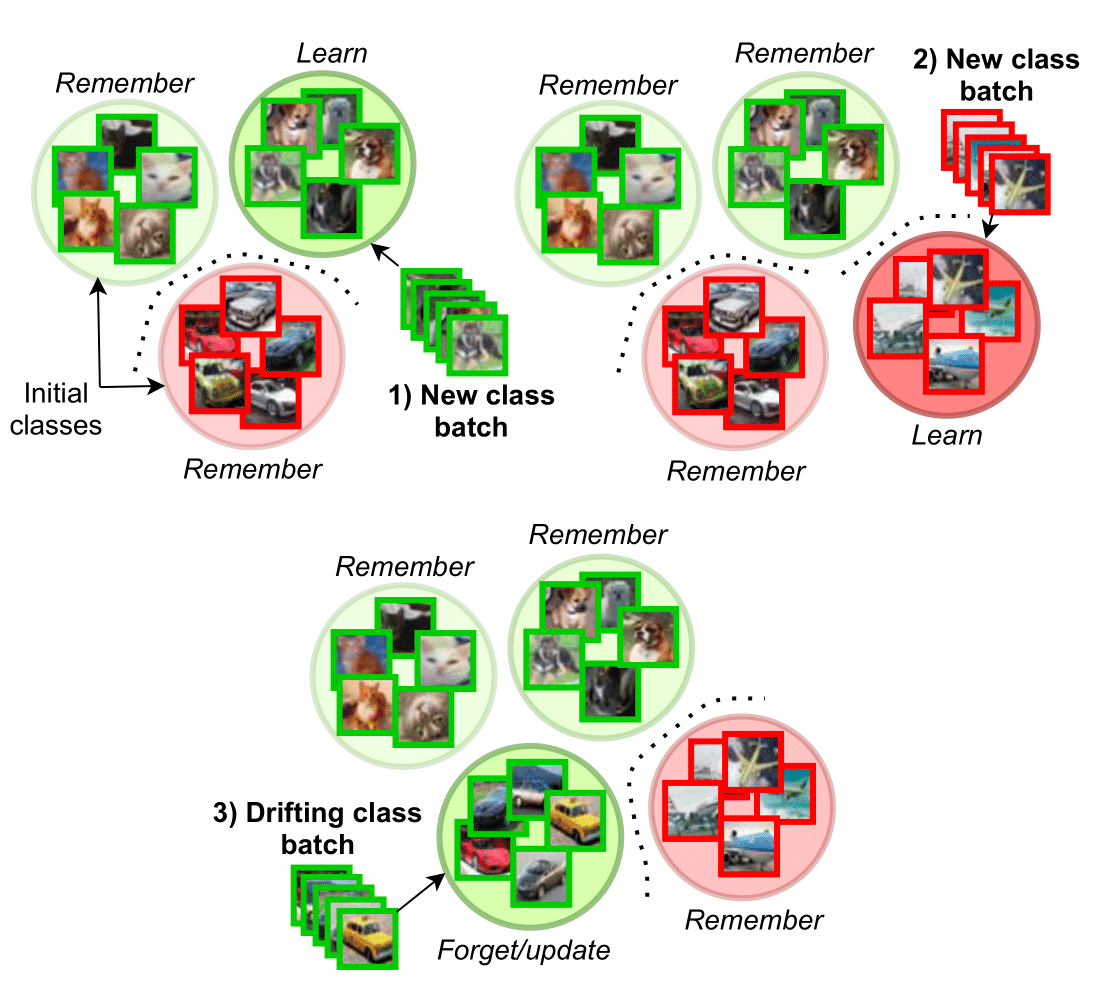
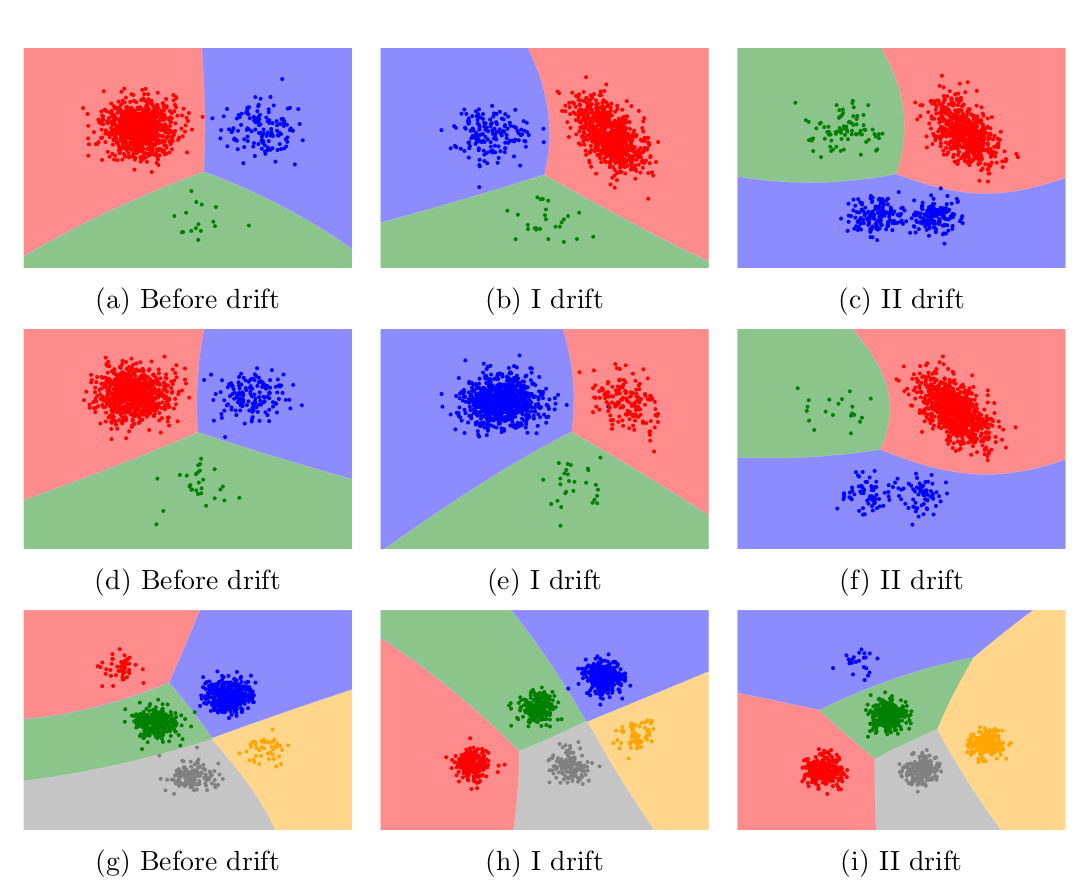
In my Ph.D. research, I have been focused on continual/lifelong learning from stationary and non-stationary data, mainly in the context of catastrophic forgetting and concept drift adaptation.
Besides my academic experience, I was a SWE/ML intern at Facebook, working with the Ads Core ML team on large-scale entity relation classification using semantic and graph embeddings. Before starting my Ph.D., I was a software/data engineer at Nokia, in the Big Data & Network Engineering department, where I gained experience in developing commercial data-driven projects.